Project Description
This project addresses three key scalability obstacles of future Exascale systems: the vulnerability to system failures due to transient or permanent errors, the performance losses due to imbalances and the noise due to unpredictable interactions between HPC applications and the operating-system. We address these obstacles by designing, implementing and evaluating a prototypical system, which integrates three well-proven technologies:
- Microkernel-based operating systems to eliminate operating system noise impacts of feature-heavy all-in-one operating systems and to make kernel influences more deterministic and predictable,
- Erasure-code protected in-memory checkpointing to provide a fast checkpoint and restart mechanism capable of keeping up with the increase in the mean-time between failures (MTBF). We expect the MTBF to soon outrun the time needed to write traditional checkpoints onto external file systems,
- Mathematically sound MosiX management system and load balancing algorithms to adjust the system to the highly dynamic and wide variety of requirements for today's and future HPC applications.
The resulting system will be a fluid self-organizing platform for applications that require scaling up to Exascale performance. An important component of the project will be the adaptation of suitable HPC work loads to showcase our new platform. A demonstration of such applications on a prototype implementation is the primary objective of our project.
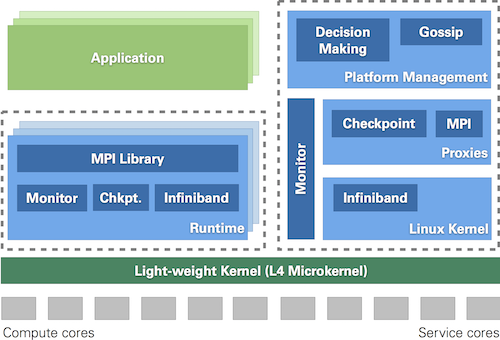
System Architecture
- Substrate based on L4 microkernel
- Performance-critical parts of MPI and XtreemFS run directly on L4
- Non-critical parts reuse Linux
- Dynamic assignment of applications to nodes at run time
- MosiX online load management
- Several cores (e.g., 100-1000) organized in multicore node (MCN)
- Most MCN cores are compute cores
- Few MCN cores (e.g., just two) are service cores (running complete Linux OS, communicate with other MCNs)
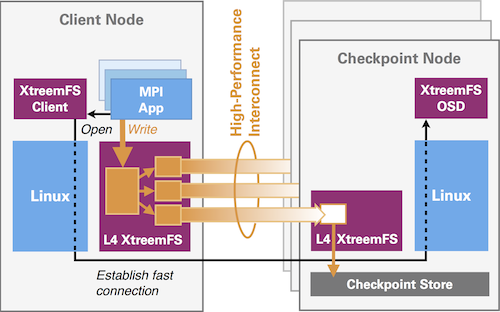
Split XtreemFS Architecture
- Adaptation for Exascale: Split based on performance criticality
- L4-based component for high-speed, low-latency data transfer
- Complex management and setup based on Linux/POSIX
- High-performance interconnect between nodes
- Distributed storage on nodes holds checkpoint state
- Erasure coding for tolerating node failures
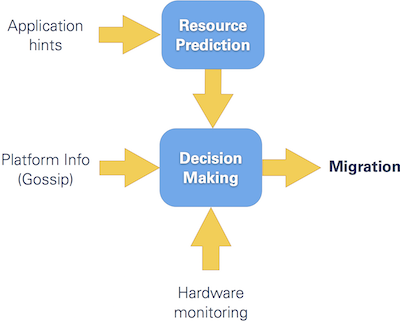
Dynamic Platform Management
- Consider CPU cycles, memory bandwidth, and other resources
- Classification based on memory load („memory dwarfs“) to optimize scheduling and placement
- Prediction of resource usage using hardware counters and application-level hints (e.g., number of particles, time steps)
Fault Tolerance
- Application interfaces to optimize or avoid C/R (e.g., hints on when to checkpoint, ability to recover from node loss)
- Node-level fault tolerance: Multiple Linux instances, micro-rebooting, pro-active migration away from failing nodes
Hardware Assumptions
- Extremely large number of components in Exascale systems
- High probability of failing cores or nodes
- Not all cores may be active simultaneously for a long time due to heat/energy constraints (dark silicon)
- Low-power storage for checkpoint state on each node